Platform Teams & Their Challenges with Data Streaming
Platform Teams & Their Challenges with Data Streaming
Platform Teams & Their Challenges with Data Streaming
Luis Galeas
Jun 28, 2024
8 Mins Read

In software organizations, platform teams enable product teams to deliver features efficiently. However, organizations working with data streaming often struggle with productivity and business risk, even when platform teams have worked extensively on data streaming and reached maturity. Platform teams fight with ongoing maintenance and complex abstractions, while product teams battle with a high level of required knowledge and complex integrations. This scenario creates significant productivity losses—often in the order of 5x to 10x for both platform and product teams—and introduces substantial business incident risk.
The Incremental Build-Up to Complexity
Organizations typically start using data streaming technologies to solve critical problems such as microservices communication, executing asynchronous workflows, and running event-driven applications. Initially, product teams manually handle much of this work, progressing to various abstractions such as Terraform templates, specific APIs, shell scripts, or runbooks. Over time, the need for more sophisticated abstractions becomes apparent, leading to the formation or expansion of platform teams dedicated to managing these technologies.
At first, a few individuals create abstractions, but as the complexity grows, so does the need for a dedicated team. The complexity leads to hiring additional engineers or reassigning existing ones to focus on platform and DevOps tasks. Platform teams create abstractions for technologies like Kafka, Pulsar, Kinesis, SQS, and RabbitMQ. With time, the focus shifts to creating better abstractions and maintaining the growing infrastructure. After 18 to 36 months, with a team of 5 or more engineers, some sense of maturity is reached. However, this maturity is at a local maximum because plenty of problems are left to solve. As mentioned before, productivity suffers, and the business is at risk of incidents.
Problems at Platform Team Maturity
Let's examine anonymized examples from Ambar's friends across the data-streaming community to explore how the status quo at maturity can be problematic. We will go through six problems, with examples that illustrate productivity losses and business risks.

1. Configuration Overload
Platform teams often maintain hundreds of configuration parameters for message brokers, producers, consumers, exchanges, connectors, sinks, and topics. Kafka alone has hundreds (more than a thousand, depending on who you ask and how you distinguish different parameters).
A real-world example: a tech lead at a healthcare services provider shared a crisis in which a single misconfiguration for the Kafka leader election violated ordering guarantees, risking the integrity of medication dispensing.

2. Abstraction Complexity
Platform teams may manage dozens of infrastructures as code templates, scripts, and runbooks to support various programming languages and product team needs. It's tough to create a one-size-fits-all solution because it would need to address thorny problems such as delivery guarantees, ordering, autoscaling (including producers, consumers, and message brokers), automated failovers, and repartitioning. Thus platform teams provide abstractions with tuning knobs that can be and will be misused.
A real-world example: The platform team maintained 72 Terraform templates at a retailer to avoid providing tuning knobs for Kafka topics. Instead of helping, this created a massive barrier to entry for anyone needing Kafka topics.
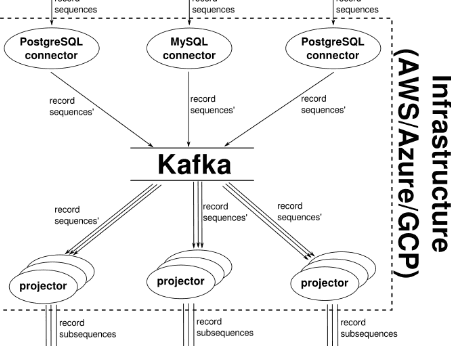
3. Operational Overhead
Teams operate, monitor, scale, secure, debug, optimize, and update dozens of compute instances for data streaming workloads. Managed services can help here, but only to an extent. Ultimately, publishers/producers and subscribers/consumers can misbehave, and the systems they interact with, such as databases, come with their issues.
A real-world example: An engineer at a supermarket deployed a new topic within the guardrails the platform team provided. The deployment happened at a quiet time for the supermarket. A single lousy producer brought the entire 3-node cluster down at peak time. Why? The combination of partition quantity, sidecars installed on each node, and excessive production led to high CPU usage, which brought one node down and cascaded to get other nodes down when they received increased stress.

4. Knowledge Requirements
Despite the abstractions for data streaming, all teams need deep data-streaming expertise, diverting focus from core competencies. The platform team needs the deepest knowledge, but product teams need to be well aware of what is going on under the hood or risk incidents.
A real-world example: A fraud monitoring company experienced a major incident due to inadequate deduplication, leading to false fraud alarms and over 500 hours spent on resolution. Inadequate deduplication resulted from unclear documentation around a subscriber abstraction for RabbitMQ.

5. Mountains of Custom Code
When third-party libraries or managed services fall short, custom solutions proliferate. Many engineers report writing thousands of lines of custom code for specific use cases, such as repartitioning topics without downtime. Connectors and sinks (known by other names outside of the Kafka ecosystem) attempt to abstract these mountains of code but do so at the price of correctness or come with their mountain of configuration parameters.
A real-world example: Over half of Ambar's friends in the data streaming community indicated they had to implement their own custom producers and consumers. One engineer recounted how his team wrote over five thousand lines of code to support repartitioning topics without experiencing downtime or losing ordering guarantees.

6. Coordination Chaos
All the "good enough" solutions that are eventually available across the company require extensive cross-team coordination. This occurs because despite best efforts and intentions, solutions are built progressively and iteratively. And full scale rewrites are almost never practical or are worthwhile due to risk.
A real-world example: a furniture retailer used change data capture (CDC) to convert inserts into "creation events" and updates into "mutation events." They used these events downstream to execute business processes. A transaction ID demarcated the boundary for a single event, but transaction boundaries changed over time. Schemas also changed over time. In practice, feature velocity decreased by 15x because of all the consensus needed to deploy one feature!
Conclusion: What To Do Instead
The state of platform teams in data streaming is fraught with inefficiencies and risks, even after reaching maturity. And it happens because of the realities of business (deadlines, staff churn, knowledge silos). This is why we created Ambar!
We offer better abstractions that platform teams can provide to their companies, simplifying real-time data streaming without requiring in-depth knowledge from product teams. And instead of needing to rewrite everything from the ground up, platform teams and their product teams can start using Ambar within 15 minutes. For more details, contact us, explore our materials, or sign up to use us.
In software organizations, platform teams enable product teams to deliver features efficiently. However, organizations working with data streaming often struggle with productivity and business risk, even when platform teams have worked extensively on data streaming and reached maturity. Platform teams fight with ongoing maintenance and complex abstractions, while product teams battle with a high level of required knowledge and complex integrations. This scenario creates significant productivity losses—often in the order of 5x to 10x for both platform and product teams—and introduces substantial business incident risk.
The Incremental Build-Up to Complexity
Organizations typically start using data streaming technologies to solve critical problems such as microservices communication, executing asynchronous workflows, and running event-driven applications. Initially, product teams manually handle much of this work, progressing to various abstractions such as Terraform templates, specific APIs, shell scripts, or runbooks. Over time, the need for more sophisticated abstractions becomes apparent, leading to the formation or expansion of platform teams dedicated to managing these technologies.
At first, a few individuals create abstractions, but as the complexity grows, so does the need for a dedicated team. The complexity leads to hiring additional engineers or reassigning existing ones to focus on platform and DevOps tasks. Platform teams create abstractions for technologies like Kafka, Pulsar, Kinesis, SQS, and RabbitMQ. With time, the focus shifts to creating better abstractions and maintaining the growing infrastructure. After 18 to 36 months, with a team of 5 or more engineers, some sense of maturity is reached. However, this maturity is at a local maximum because plenty of problems are left to solve. As mentioned before, productivity suffers, and the business is at risk of incidents.
Problems at Platform Team Maturity
Let's examine anonymized examples from Ambar's friends across the data-streaming community to explore how the status quo at maturity can be problematic. We will go through six problems, with examples that illustrate productivity losses and business risks.
1. Configuration Overload
Platform teams often maintain hundreds of configuration parameters for message brokers, producers, consumers, exchanges, connectors, sinks, and topics. Kafka alone has hundreds (more than a thousand, depending on who you ask and how you distinguish different parameters).
A real-world example: a tech lead at a healthcare services provider shared a crisis in which a single misconfiguration for the Kafka leader election violated ordering guarantees, risking the integrity of medication dispensing.
2. Abstraction Complexity
Platform teams may manage dozens of infrastructures as code templates, scripts, and runbooks to support various programming languages and product team needs. It's tough to create a one-size-fits-all solution because it would need to address thorny problems such as delivery guarantees, ordering, autoscaling (including producers, consumers, and message brokers), automated failovers, and repartitioning. Thus platform teams provide abstractions with tuning knobs that can be and will be misused.
A real-world example: The platform team maintained 72 Terraform templates at a retailer to avoid providing tuning knobs for Kafka topics. Instead of helping, this created a massive barrier to entry for anyone needing Kafka topics.
3. Operational Overhead
Teams operate, monitor, scale, secure, debug, optimize, and update dozens of compute instances for data streaming workloads. Managed services can help here, but only to an extent. Ultimately, publishers/producers and subscribers/consumers can misbehave, and the systems they interact with, such as databases, come with their issues.
A real-world example: An engineer at a supermarket deployed a new topic within the guardrails the platform team provided. The deployment happened at a quiet time for the supermarket. A single lousy producer brought the entire 3-node cluster down at peak time. Why? The combination of partition quantity, sidecars installed on each node, and excessive production led to high CPU usage, which brought one node down and cascaded to get other nodes down when they received increased stress.
4. Knowledge Requirements
Despite the abstractions for data streaming, all teams need deep data-streaming expertise, diverting focus from core competencies. The platform team needs the deepest knowledge, but product teams need to be well aware of what is going on under the hood or risk incidents.
A real-world example: A fraud monitoring company experienced a major incident due to inadequate deduplication, leading to false fraud alarms and over 500 hours spent on resolution. Inadequate deduplication resulted from unclear documentation around a subscriber abstraction for RabbitMQ.
5. Mountains of Custom Code
When third-party libraries or managed services fall short, custom solutions proliferate. Many engineers report writing thousands of lines of custom code for specific use cases, such as repartitioning topics without downtime. Connectors and sinks (known by other names outside of the Kafka ecosystem) attempt to abstract these mountains of code but do so at the price of correctness or come with their mountain of configuration parameters.
A real-world example: Over half of Ambar's friends in the data streaming community indicated they had to implement their own custom producers and consumers. One engineer recounted how his team wrote over five thousand lines of code to support repartitioning topics without experiencing downtime or losing ordering guarantees.
6. Coordination Chaos
All the "good enough" solutions that are eventually available across the company require extensive cross-team coordination. This occurs because despite best efforts and intentions, solutions are built progressively and iteratively. And full scale rewrites are almost never practical or are worthwhile due to risk.
A real-world example: a furniture retailer used change data capture (CDC) to convert inserts into "creation events" and updates into "mutation events." They used these events downstream to execute business processes. A transaction ID demarcated the boundary for a single event, but transaction boundaries changed over time. Schemas also changed over time. In practice, feature velocity decreased by 15x because of all the consensus needed to deploy one feature!
Conclusion: What To Do Instead
The state of platform teams in data streaming is fraught with inefficiencies and risks, even after reaching maturity. And it happens because of the realities of business (deadlines, staff churn, knowledge silos). This is why we created Ambar!
We offer better abstractions that platform teams can provide to their companies, simplifying real-time data streaming without requiring in-depth knowledge from product teams. And instead of needing to rewrite everything from the ground up, platform teams and their product teams can start using Ambar within 15 minutes. For more details, contact us, explore our materials, or sign up to use us.