How Ambar Streaming Works
How Ambar Streaming Works
How Ambar Streaming Works
Marcelo Lazaroni
Aug 26, 2024
7 Mins Read

Ambar replaces your entire queuing infrastructure with a minimal configuration setup. It provides delivery and ordering guarantees out of the box, avoiding nasty bugs and allowing engineering teams to focus on business-critical work instead of managing infrastructure.
Using Ambar means no more fiddling with Kafka or RabbitMQ servers, worrying about consumer options, or cluster backups. But that's just part of it. It also makes emitting and consuming records convenient and safe, allowing our users to build scalable mission-critical real-time applications in minutes. And for the record, Ambar uses Kafka under the hood.
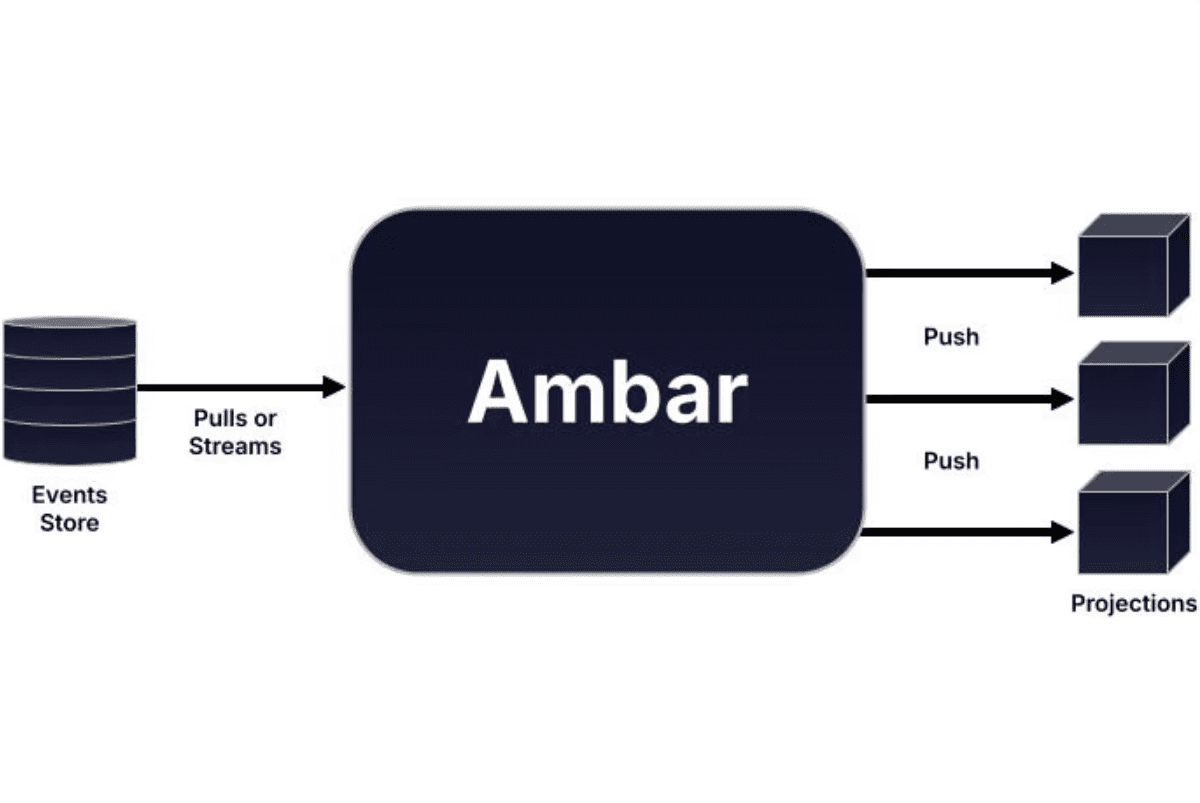
Instead of producing to and consuming from message brokers, Ambar pulls records from databases and pushes them to application endpoints via HTTP, abstracting away your queueing infra entirely.
To use Ambar, you provide three things:
Data Sources: durable storage containing record streams. For example, an append-only table in your relational database where each row is one record.
Filters: logical specifications that select subsets of records from data sources.
Data Destinations: endpoints in your application that will process your record streams.
Did you notice there is no configuration of message broking internals or its consumers? How many partitions? How many clusters? What about batching options? How about polling intervals or offset auto-commits?
Ambar uses safe defaults and custom ingress and egress mechanisms to service throughputs ranging from a few gigabytes per year to terabytes per hour. And it covers your key concerns out-of-the-box:
Nine 9s of durability
99.99% availability
Infinite retention
Sub 25ms latency (after an initial snapshot, we use your database's changelog to stream records with low latency)
Data Sources
An Ambar data source contains records that will be delivered to data destinations. All records belong to some sequence identified by a record property called the sequence ID. Additionally, records may contain an arbitrary number of additional fields that store application-relevant data. If you are familiar with other messaging platforms, think of a sequence as a stream where the sequence ID is simply a partitioning key that uniquely identifies that stream.
You can concurrently append to sequences with different IDs, but each append is made to the end of each sequence, effectively preventing the mutation of old records.
Data Destinations
An Ambar data destination is an HTTP service to which a filtered set of records will be streamed. Each data destination is composed of a set of filters that select desired records from a data source. Ambar has an intuitive and powerful domain-specific language for specifying filters in record fields.
Data destinations also adapt dynamically to the available processing power on customer endpoints, ensuring that customers can achieve the highest throughput possible without overloading their systems (read more about it here).
The End Result
The resulting architecture is simple and elegant. Your application writes to a database, while your data processors receive records with minimal latency, with delivery and ordering guarantees, and at an optimal rate. This simplicity has wide-ranging consequences:
No rebalances. The push model allows consuming machines to scale up and down without affecting message delivery.
Rebuilding a view model from scratch doesn't put any load on your main database. Ambar has infinite retention, so replaying records from a data source doesn't require fetching anything from your database.
Ambar is compatible with any language and framework. There is no SDK to install or library to use. Write to your database as you normally would and receive those records via HTTP.
24/7 Monitoring & Support. We provide the infrastructure and care for it so your team can focus on driving value to your business, not getting a PhD in Kafka and similar technologies.
Easy exactly-once semantics. Ambar provides the at-least-once delivery guarantees. With that, it's a small step for a data consumer to implement exactly once semantics.
Elastic capacity. Ambar automatically scales up and down to meet your consumption capacity. Consume faster by just growing your consumer fleet.
Confidence in the system's durability, availability, latency, and retention characteristics. No more worrying about how that config you weren't sure about could come back to bite you.
Get in touch to discuss how Ambar can help your business, or sign up to get started for free
Ambar replaces your entire queuing infrastructure with a minimal configuration setup. It provides delivery and ordering guarantees out of the box, avoiding nasty bugs and allowing engineering teams to focus on business-critical work instead of managing infrastructure.
Using Ambar means no more fiddling with Kafka or RabbitMQ servers, worrying about consumer options, or cluster backups. But that's just part of it. It also makes emitting and consuming records convenient and safe, allowing our users to build scalable mission-critical real-time applications in minutes. And for the record, Ambar uses Kafka under the hood.
Instead of producing to and consuming from message brokers, Ambar pulls records from databases and pushes them to application endpoints via HTTP, abstracting away your queueing infra entirely.
To use Ambar, you provide three things:
Data Sources: durable storage containing record streams. For example, an append-only table in your relational database where each row is one record.
Filters: logical specifications that select subsets of records from data sources.
Data Destinations: endpoints in your application that will process your record streams.
Did you notice there is no configuration of message broking internals or its consumers? How many partitions? How many clusters? What about batching options? How about polling intervals or offset auto-commits?
Ambar uses safe defaults and custom ingress and egress mechanisms to service throughputs ranging from a few gigabytes per year to terabytes per hour. And it covers your key concerns out-of-the-box:
Nine 9s of durability
99.99% availability
Infinite retention
Sub 25ms latency (after an initial snapshot, we use your database's changelog to stream records with low latency)
Data Sources
An Ambar data source contains records that will be delivered to data destinations. All records belong to some sequence identified by a record property called the sequence ID. Additionally, records may contain an arbitrary number of additional fields that store application-relevant data. If you are familiar with other messaging platforms, think of a sequence as a stream where the sequence ID is simply a partitioning key that uniquely identifies that stream.
You can concurrently append to sequences with different IDs, but each append is made to the end of each sequence, effectively preventing the mutation of old records.
Data Destinations
An Ambar data destination is an HTTP service to which a filtered set of records will be streamed. Each data destination is composed of a set of filters that select desired records from a data source. Ambar has an intuitive and powerful domain-specific language for specifying filters in record fields.
Data destinations also adapt dynamically to the available processing power on customer endpoints, ensuring that customers can achieve the highest throughput possible without overloading their systems (read more about it here).
The End Result
The resulting architecture is simple and elegant. Your application writes to a database, while your data processors receive records with minimal latency, with delivery and ordering guarantees, and at an optimal rate. This simplicity has wide-ranging consequences:
No rebalances. The push model allows consuming machines to scale up and down without affecting message delivery.
Rebuilding a view model from scratch doesn't put any load on your main database. Ambar has infinite retention, so replaying records from a data source doesn't require fetching anything from your database.
Ambar is compatible with any language and framework. There is no SDK to install or library to use. Write to your database as you normally would and receive those records via HTTP.
24/7 Monitoring & Support. We provide the infrastructure and care for it so your team can focus on driving value to your business, not getting a PhD in Kafka and similar technologies.
Easy exactly-once semantics. Ambar provides the at-least-once delivery guarantees. With that, it's a small step for a data consumer to implement exactly once semantics.
Elastic capacity. Ambar automatically scales up and down to meet your consumption capacity. Consume faster by just growing your consumer fleet.
Confidence in the system's durability, availability, latency, and retention characteristics. No more worrying about how that config you weren't sure about could come back to bite you.
Get in touch to discuss how Ambar can help your business, or sign up to get started for free